Teaching GitHub Copilot New SQL Dialects with Reusable Prompts
Published on
Have you ever struggled with GenAI tools generating incorrect or unusable code for your internal SDK or API?
It’s not unexpected. While these tools can provide good results when given enough context, they would have to guess the unknown syntax or API surface for the things unfamiliar to them.
Recently, a customer approached me with exactly this issue. They distribute their SDK as a binary package with detailed documentation, yet existing GenAI have zero knowledge of their SDK, leading to poor developer experiences. A customer was looking for a way to improve the situation, and it sounded like a fun challenge.
I decided to tackle this problem head-on by creating a practical prototype using DuckDB, a database engine that is new and rare enough, so that existing LLMs have little if not no knowledge about it. I chose DuckDB for this experiment, because it has a so-called “Friendly SQL” syntax, which is a syntactic sugar on top of the standard PostgreSQL.
My goal was simple: help GitHub Copilot generate accurate DuckDB-compatible SQL queries using reusable prompts and LLM-friendly documentation.
The Problem: Vanilla SQL vs. DuckDB SQL
By default, Copilot generates standard “Vanilla” SQL queries. For example, when asked to create a table, it typically suggests something like this:
DROP TABLE IF EXISTS my_table;
CREATE TABLE my_table (...);
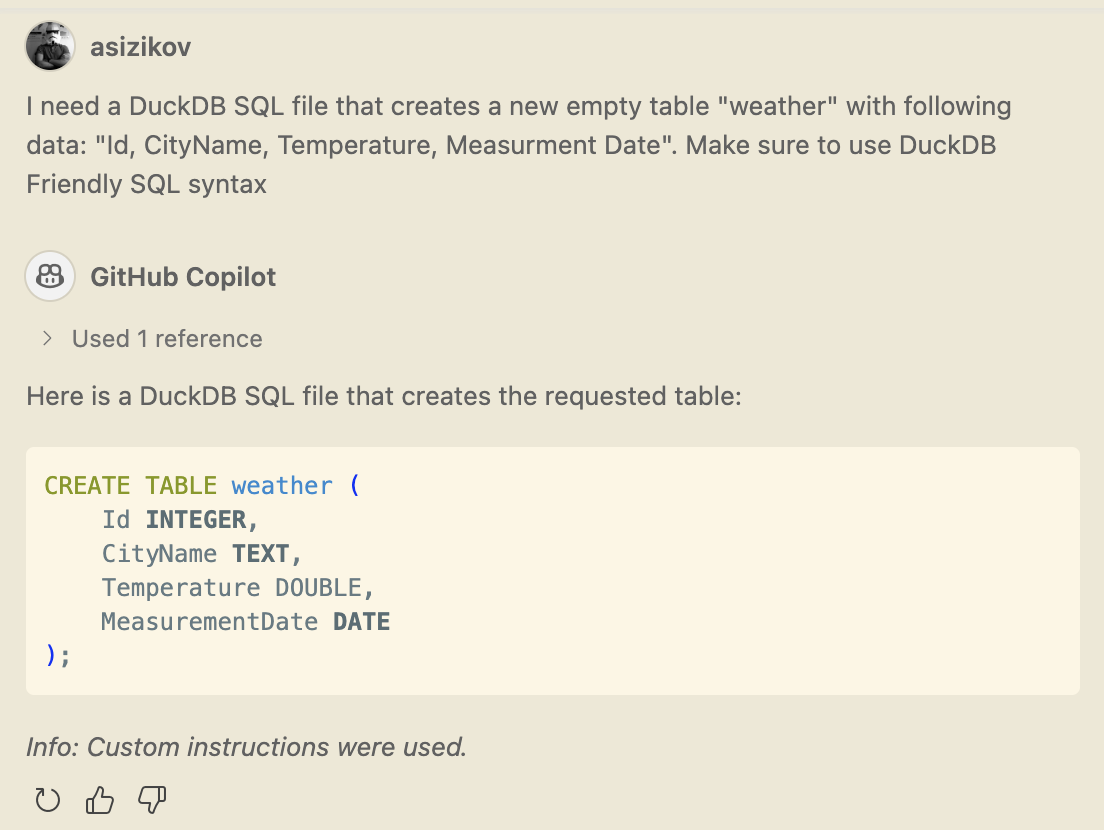
As you can see, despite me asking to use Friendly SQL syntax Copilot generated a vanilla SQL query. Something that I expected of course.
DuckDB provides a more convenient syntax:
CREATE OR REPLACE TABLE my_table (...);
Let’s see how we can “teach” Copilot to generate SQL in DuckDB-specific syntax automatically without fine-tuning the model.
My Approach: Reusable Prompts and Compact Documentation
To achieve this, I leveraged an experimental VS Code feature called “Reusable Prompts.” These prompts allow you to provide additional instructions and even include external files as context, helping Copilot understand and generate code in specific dialects or frameworks.
Here’s how I did it:
Extracting Documentation: I started by extracting DuckDB’s SQL dialect documentation from the official DuckDB docs. However, the full documentation was extensive—over 50,000 lines—far too large for practical use as a prompt.
Compressing Documentation: To make the documentation manageable, I compressed it using the Sonnet 3.7 Thinking model. My goal was to retain essential features and syntax details while significantly reducing the size.
Creating a Reusable Prompt: I then created a reusable prompt referencing our compacted DuckDB SQL documentation. This prompt instructs Copilot explicitly to use DuckDB-specific syntax whenever generating SQL queries.
Deep Dive: LLM-Friendly Documentation
LLM-tools cannot only rely on the training data set, there is always something new or proprietary that is not included in the training data. Some folks are proposing to provide /llm links with the AI-agent readable documentation in simple plain text format.
More on this proposal on the llmstxt.org site.
Some sites are already attempting to build a catalogue of LLM-TXT docs. For example llmstxt.site hosts such collection.
I extracted the DuckDB SQL dialect documentation from DuckDB Docs and saved it locally for future processing.
However, the full reference is too extensive (over 50k lines) to use directly as a prompt. Instead, I cleaned it up by copying only the SQL reference to the local file. This gave me ~750 lines of documentation, which is probably still too long to be included in every prompt.
Deep Dive: Compressing Documentation
The SQL reference remains quite verbose, with many examples and extra details that can overwhelm models.
I used the Sonnet 3.7 Thinking model with the following prompt:
Your job is to read the #file:sql-dialect.md file that contains DuckDB syntax, based on the standard PostgreSQL flavor.
Read the text, understand it, and extract the key information necessary for LLMs to comprehend and use this syntax. Write this information to the #file:sql-dialect-compressed.md file.
- The file must be as compact as possible to save tokens.
- It must include all essential features without omitting important details.
This model is large enough to get the provided documentation and compress it into a more manageable size. The result was a significantly smaller file (under 100 lines), retaining the essential features and syntax details.
The compressed file can now be included into the Docs folder in my test repository.
Deep Dive: Reusable Prompts
Once the compressed doc was created, I added a reusable prompt (duckdb.prompt.md) applicable to any DuckDB SQL-related request.
Reusable prompts are an experimental VS Code feature. For more details, see this documentation.
A neat feature is that reusable prompts can reference external files; in this case, a SQL reference document.
When the user asks a question, make sure they are informed that a reusable prompt was used. Include this note at the beginning of the answer.
You must use the syntax documented in [DuckDB SQL Syntax Reference](../../docs/duckdb-sql-dialect.md). If these instructions are missing, inform the user.
Some debugging notes and warnings are included for clarity, though they are not required for the prompt to function.
Reusable prompts can be attached to any conversation as context.
While it’s now possible to append the compressed SQL reference to the local copilot-instructions, I prefer to keep it separate, as it allows me to skip it for generic, non-DuckDB SQL related requests.
Additional Improvements
I also updated my copilot-instructions.md file and added an instruction to remind users to utilize Reusable Prompts when DuckDB SQL code is requested.
- If the user requests DuckDB SQL code and the prompt lacks SQL documentation, remind them to include the Reusable Prompt (duckdb.prompt.md).
Results: Improved Developer Experience
The results were quite satifying.
Even the GPT-4o Basic model, when provided with our reusable prompt, started generating accurate DuckDB SQL queries. Developers no longer need to manually adjust generated queries, saving time and reducing frustration.
Here’s an example of the improved output:
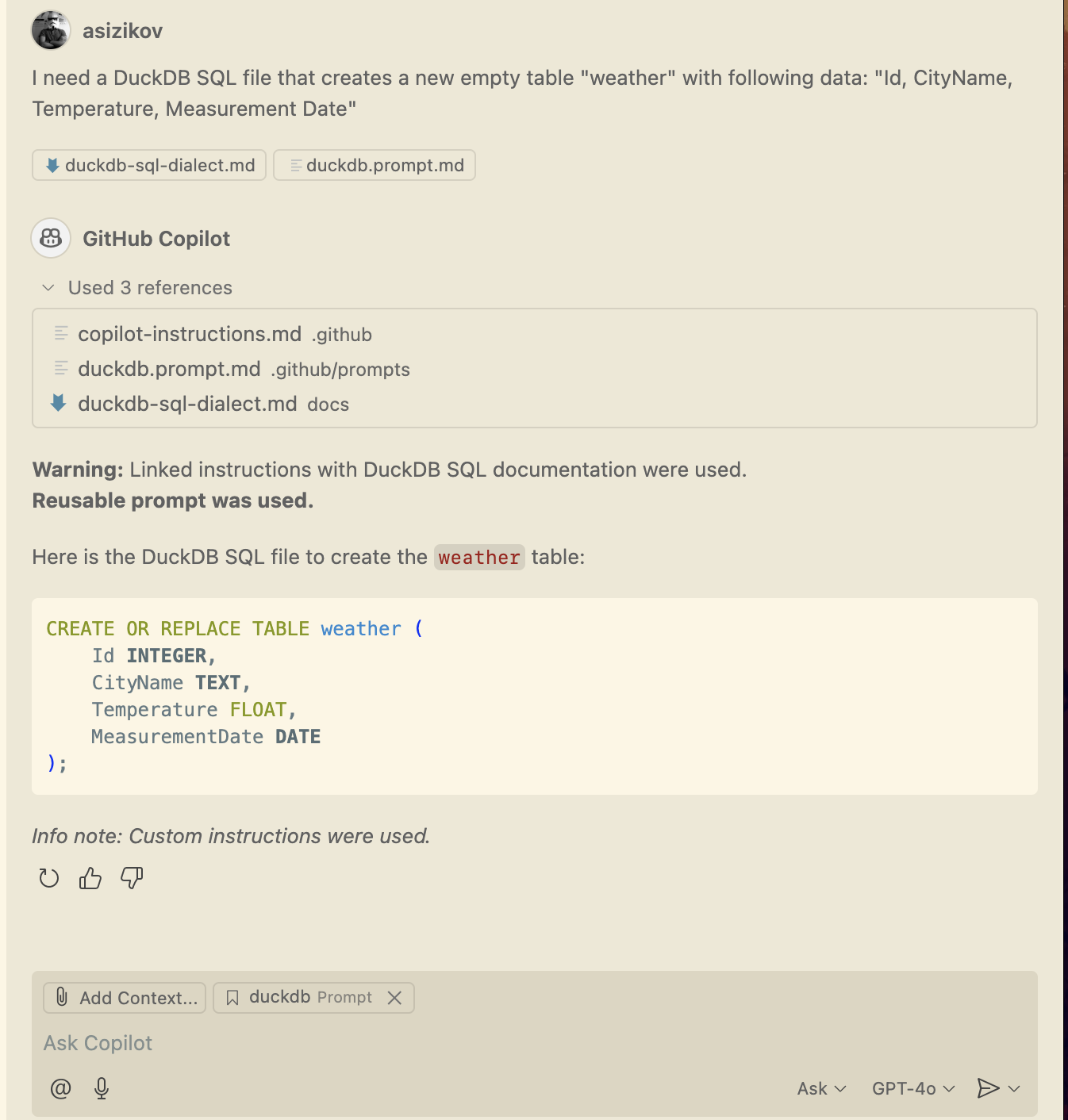
Happy coding!
Disclosure
I’m employed by GitHub at the time of writing this post. All opinions are my own.